One important factor in the performance of a robot chef is how it perceives the environment. The perceived information is than further used to make decisions and manipulate the environment by the robot. A robot chef can acquire knowledge from the environment through various modalities. We have focused on three modalities which are visual, audio, and touch.
We have currently published work in visual perception for robotic manipulation in two different aspects: video understanding and ingredient state recognition.
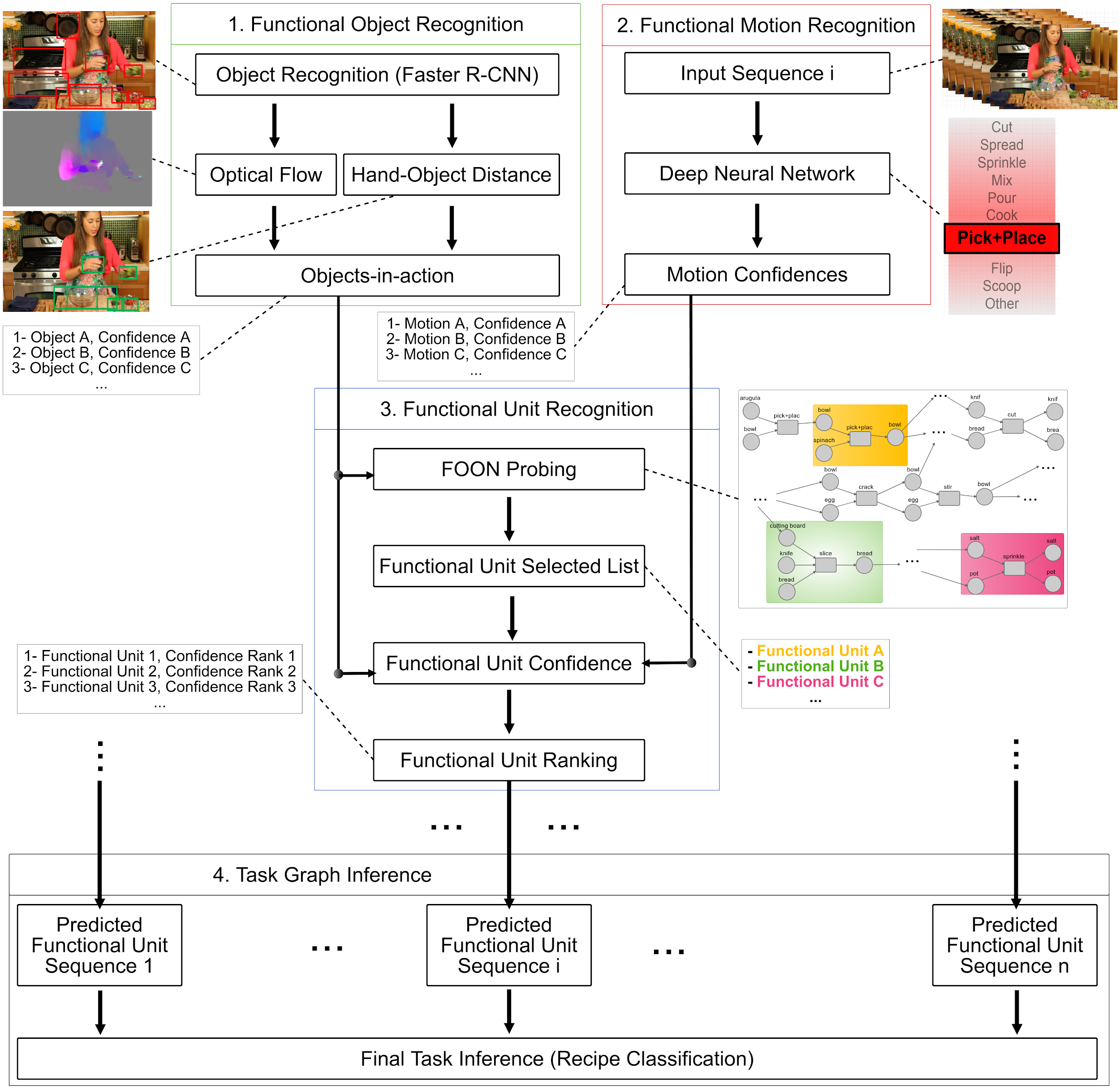
Video understanding for semi-automatic knowledge extraction: Long Activity Video Understanding Using Functional Object-Oriented Network
Video understanding is one of the most challenging topics in computer vision. In this paper, a four-stage video understanding pipeline is presented to simultaneously recognize all atomic actions and the single ongoing activity in a video. This pipeline uses objects and motions from the video and a graph-based knowledge representation network as prior reference. Two deep networks are trained to identify objects and motions in each video sequence associated with an action and low level image features are used to identify objects of interest in the video sequence. Confidence scores are assigned to objects of interest to represent their involvement in the action and to motion classes based on results from a deep neural network that classifies an ongoing action in video into motion classes. Confidence scores are computed for each candidate functional unit to associate them with an action using a knowledge representation network, object confidences, and motion confidences. Each action, therefore, is associated with a functional unit, and the sequence of actions is evaluated to identify the sole activity occurring in the video. The knowledge representation used in the pipeline is called the functional object-oriented network, which is a graph-based network useful for encoding knowledge about manipulation tasks. Experiments are performed on a dataset of cooking videos to test the proposed algorithm with action inference and activity classification. Experiments show that using a functional object-oriented network improves video understanding significantly.
States identification of cooking ingredients: Identifying Object States in Cooking-Related Images
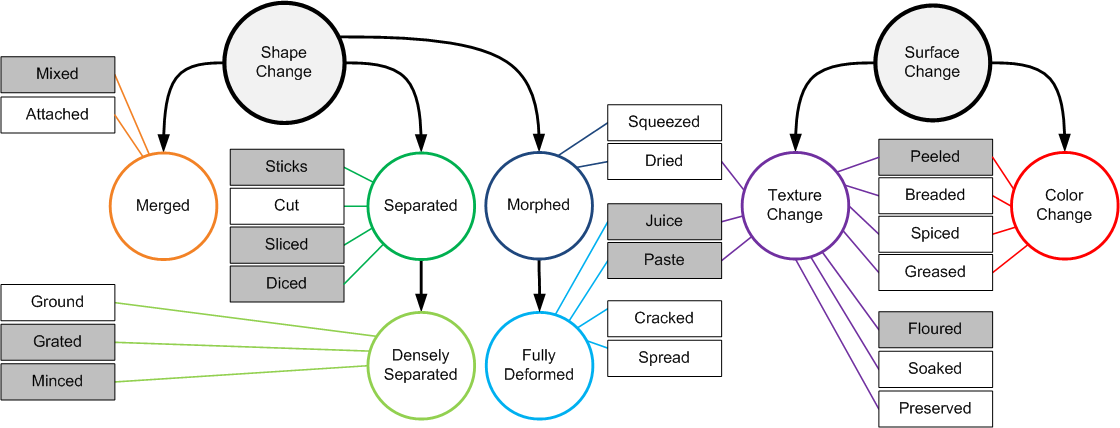
Understanding object states is as important as object recognition for robotic task planning and manipulation. To our knowledge, this paper explicitly introduces and addresses the state identification problem in cooking related images for the first time. In this paper, objects and ingredients in cooking videos are explored and the most frequent objects are analyzed. Eleven states from the most frequent cooking objects are examined and a dataset of images containing those objects and their states is created. As a solution to the state identification problem, a Resnet based deep model is proposed. The model is initialized with Imagenet weights and trained on the dataset of eleven classes. The trained state identification model is evaluated on a subset of the Imagenet dataset and state labels are provided using a combination of the model with manual checking. Moreover, an individual model is fine-tuned for each object in the dataset using the weights from the initially trained model and object-specific images, where significant improvement is demonstrated.
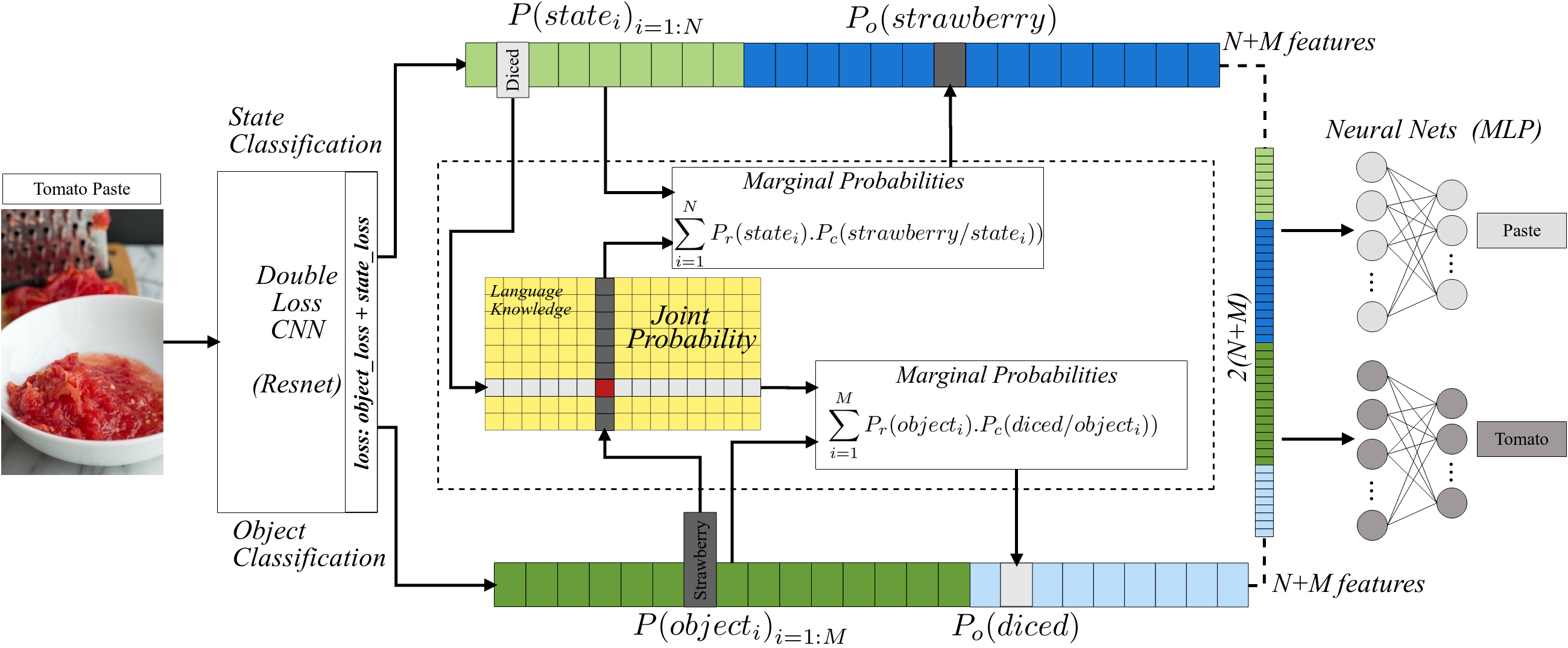
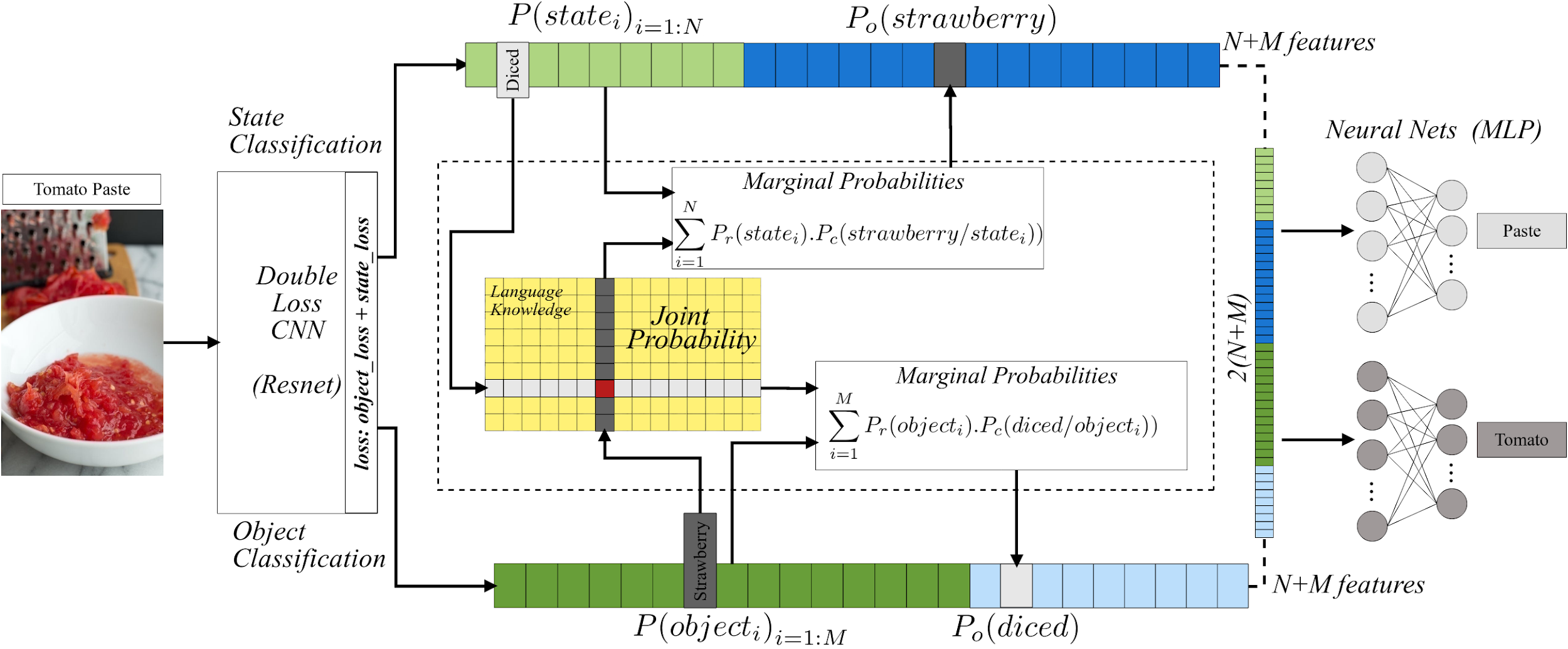
Joint Object and State Recognition using Language Knowledge
The state of an object is an important piece of knowledge in robotics applications. States and objects are intertwined together, meaning that object information can help recognize the state of an image and vice versa. This paper addresses the state identification problem in cooking related images and uses state and object predictions together to improve the classification accuracy of objects and their states from a single image. The pipeline presented in this paper includes a CNN with a double classification layer and the Concept-Net language knowledge graph on top. The language knowledge creates a semantic likelihood between objects and states. The resulting object and state confidences from the deep architecture are used together with object and state relatedness estimates from a language knowledge graph to produce marginal probabilities for objects and states. The marginal probabilities and confidences of objects (or states) are fused together to improve the final object (or state) classification results. Experiments on a dataset of cooking objects show that using a language knowledge graph on top of a deep neural network effectively enhances object and state classification.
Publication List
[2] Ahmad Babaeian Jelodar, Yu Sun, “Joint Object and State Recognition Using Language Knowledge”, IEEE International Conference on Image Processing (ICIP), August 2019.
In this paper, cooking objects and their states are jointly identified in a single image. A deep based model and marginal probabilities of states and objects using a language representation are used to enhance object and state recognition performance. Experiments on our own cooking dataset show that using a language knowledge graph with a deep neural network effectively enhances object and state classification.
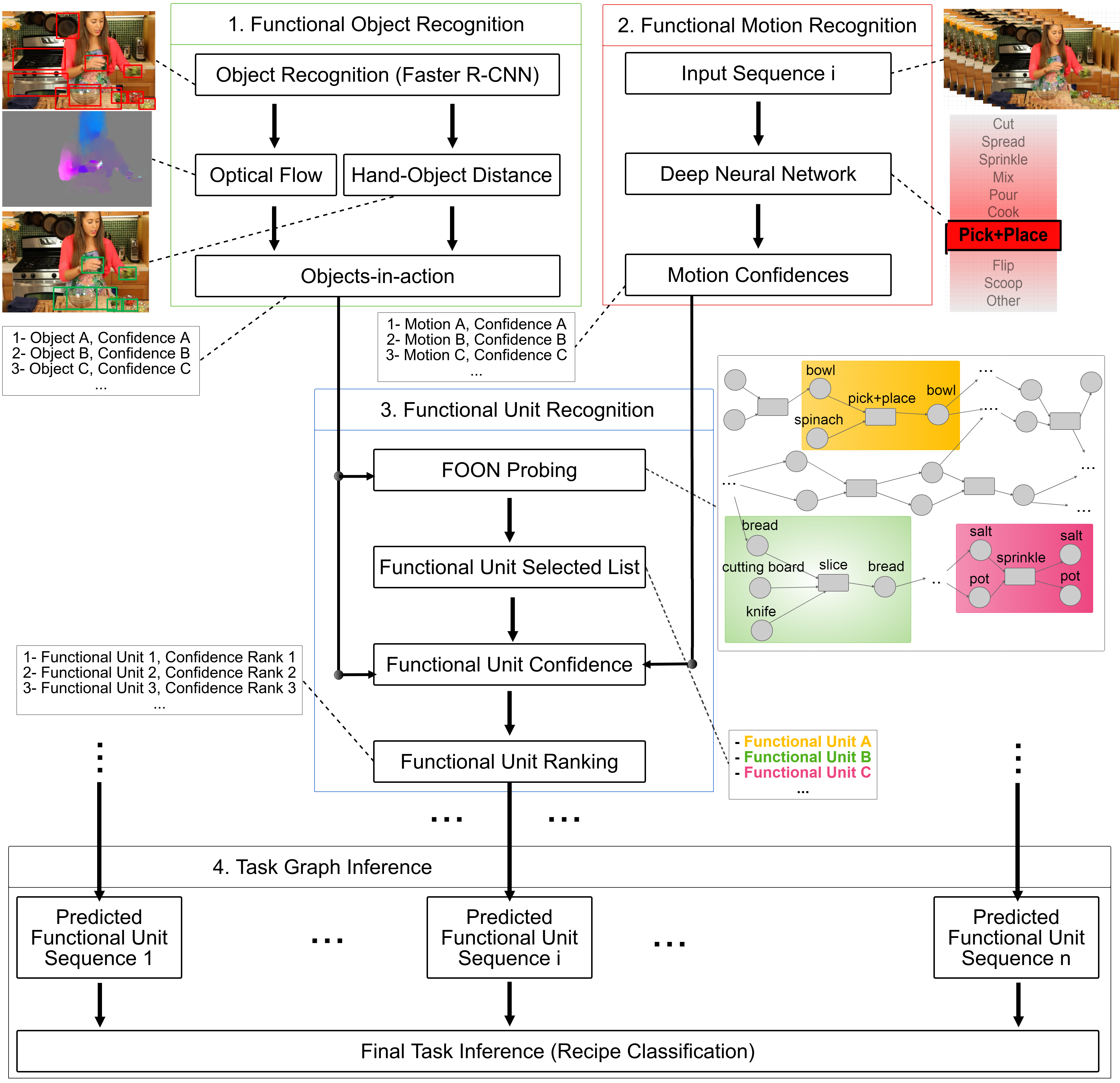
[1] Ahmad Babaeian Jelodar, David Paulius, Yu Sun, “Long activity video understanding using functional object-oriented network”, IEEE Transactions on Multimedia, May 2018.
In this paper, a four-stage video understanding pipeline is presented to simultaneously recognize all atomic actions and the single ongoing activity in a video. This pipeline uses objects and motions from the video with two parallel deep networks (Faster RCNN, CNN+LSTM) and our graph-based knowledge representation network (FOON) as prior reference. Experiments performed on a dataset of cooking videos show that using a functional object-oriented network improves video understanding significantly.