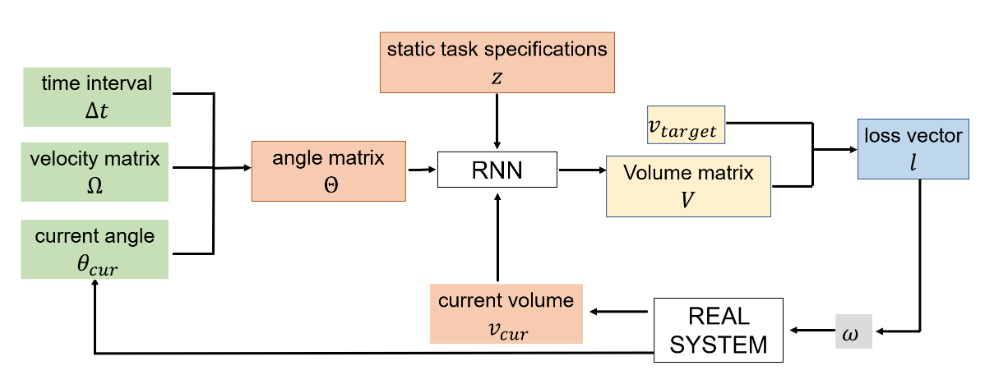
Lying at the very bottom of the robotic cooking pipeline is the manipulation of objects: an object is attached to or be held by the end effector of a robot and is manipulated to interact with other objects. The manipulation process requires control commands which are executed by the robotic system, and the control commands are the very variables that the manipulation process generates. Naively, a manipulation algorithm generates a fixed trajectory which is firmly executed. Realistically, the interactive nature of the manipulation process requires it to react to how the interaction actually goes by adjusting the control commands ad-hoc.
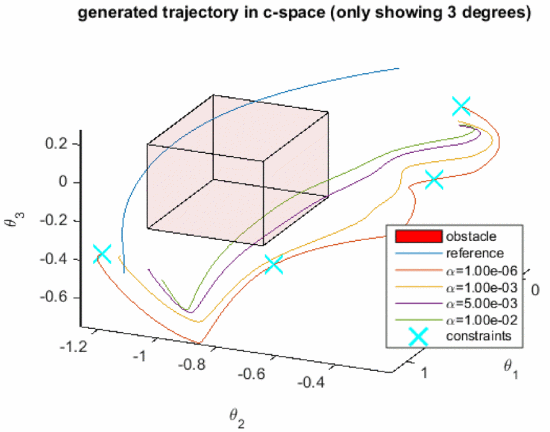
To generate a fixed trajectory for the manipulation process to follow, we need representation for the trajectory. The representation consists of certain parameters, and we determine the parameters by learning from demonstration trajectories that have been previously collected. We use functional basis to represent a trajectory in order to preserve its continuity. We use functional principal component analysis (fPCA) to determine the basis that carry most of the variation in the demonstrations. To generate a new trajectory, we search for the weight for the basis so that the resulting trajectory achieves a balance between meeting user-defined constraints and resembling demonstration data, through a hyperparameter alpha. The figure below shows the effect of alpha on the resulting trajectory, guided by the via points plotted as cyan crosses.
Publication List
[4] T. Chen, Y. Huang and Y. Sun, " Accurate Pouring using Model Predictive Control Enabled by Recurrent Neural Network," 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 2019, pp. 7682-7688.
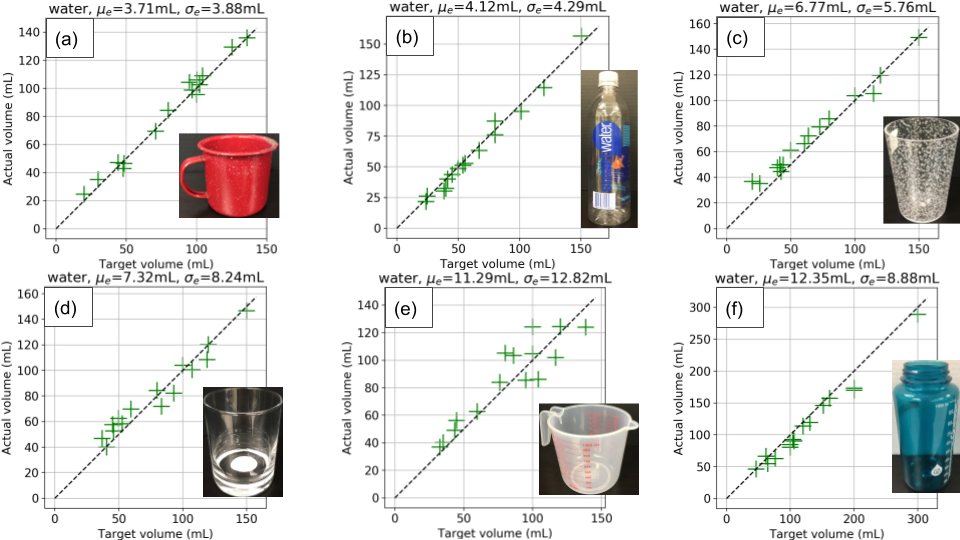
This paper presented a model predictive controller (MPC) for accurate pouring. The model of the dynamics of water in the receiving container was identified using a recurrent neural network (RNN). The output of the network was used to establish the control signal that could achieve the correct target volume. The MPC averaged a pouring error of 16.4mL over 5 different source containers.
[3] Huang, Y., & Sun, Y. (2019). A dataset of daily interactive manipulation. The International Journal of Robotics Research, 38(8), 879–886.
This paper proposed a dataset of daily interactive manipulation. Data was collected from human demonstrations. The dataset focuses on the position, orientation, force, and torque of objects manipulated in daily tasks. The dataset includes 1,603 trials of 32 types of daily motions and 1,596 trials of pouring alone.
[2] Y. Huang and Y. Sun, "Learning to pour," 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, 2017, pp. 7005-7010.
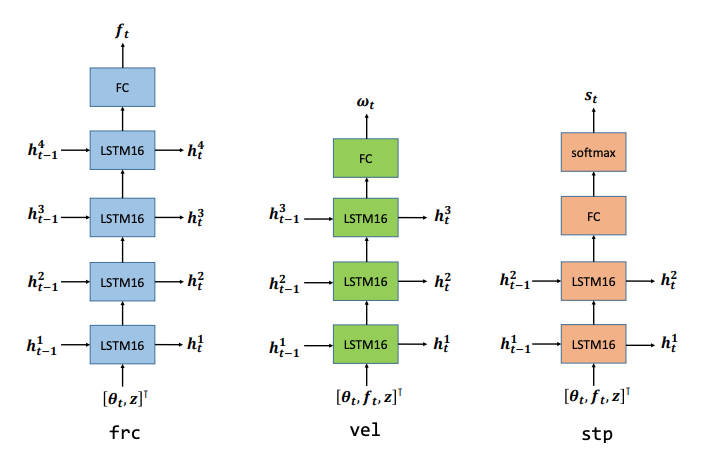
This paper presents a pouring trajectory generation approach. The approach uses recurrent neural networks as its building blocks. Simulation was used to estimate the force in the receiving container. The simulated experiments show that the system is able to generalize when either a cup, a container, or the material changes.
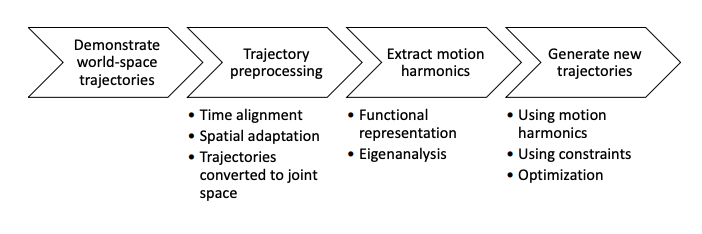
[1] Y. Huang and Y. Sun, “Generating manipulation trajectory using motion harmonics,” in 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Sept 2015, pp. 4949–4954.
In this paper, a new manipulation trajectory generating algorithm was proposed. The algorithm constructs trajectories from learned motion harmonics and user defined constraints. Eigenanalysis was used to learn motion harmonics from demonstrated motions. Then, the motion harmonics were used to compute the optimal trajectory that resembles the demonstrated motions and also satisfies the constraints.